4ParadigmSage
4Paradigm SHIFT
4Paradigm AlGS
关于第四范式
投资者关系
语言
视频简介
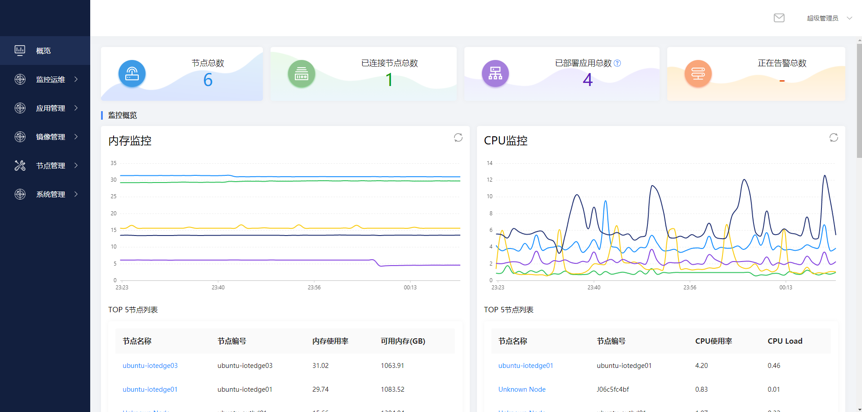
第四范式Sage IOT Edge,为用户提供深入行业应用场景的云边协同一体化服务.让企业决策更高效,赋能行业新升级。