Rank List
The top-10 teams of the competition (and the github URL to their solutions) are:
| Rank | Team Name | github URL |
| 1 | DeepBlueAI (DeepSmart) | https://github.com/DeepBlueAI/AutoSmart |
| 2 | NUS-Xtra-Lab (xuechengxi) | https://github.com/shuyao95/kddcup2019-automl.git |
| 3 | admin | https://github.com/DominickZhang/KDDCup2019_admin |
| 4 | ts302_team | https://github.com/ts302team/KDDCUP2019-AutoMLTrack |
| 5 | yoshikawa | https://github.com/pfnet-research/KDD-Cup-AutoML-5 |
| 6 | Alpha | https://github.com/luosuiqian/sample_code_submission |
| 7 | teews | https://github.com/teews-ly/Kdd-Cup-2019-automl |
| 8 | PASA_NJU | https://github.com/guojixu/KDD-Cup-2019-AutoML-Solution |
| 9 | _CHAOS_ | https://github.com/SpongebBob/AutoTableGBDT |
| 10 | IIIS_FLY | https://github.com/shuhantao/KDD2019-Challenge |
Notice June 10, 2019
We have restarted the AutoML Phase of KDD Cup 2019 AutoML Challenge(AutoML for Temporal Relational Data).
- Please visit the new challenge website(https://codalab.lri.fr/competitions/559),and take the following steps to make a re-submission of your final solution:
- - Register a new CodaLab account: please register a new CodaLab account with EXACTLY the same email address that you used for your former account (i.e., the email address with which you receive THIS email). The former team name will be retained (according to the confirmation email you sent us at the end of the Feedback Phase). Nevertheless, we strongly suggest that you use the same ID you used formerly (i.e., the team name) if it is possible.
- Submit your solution: please submit your final solution on the new challenge website. Please note:
- - All teams SHOULD make this submission, regardless of the result (“finished” or “failed”) of its former submissions (the last submission in the Feedback Phase or the re-submission in the Check phase). In other words, even if its last submission did not fail, a team should make a new submission of its final solution on the new website;
- - A team has and only has ONE chance of submission, no matter the results. Any additional submissions will be ignored. Each submission will be rerun at most *3* times if it fails (failures caused by system issues do not count);
- - The submission deadline is 11:59pm, July 13th (UTC).
- - The testing environment is exactly the same as the previous one
- - Fill out the fact sheet: please fill out the fact sheet onhttps://forms.office.com/Pages/ResponsePage.aspx?id=DQSIkWdsW0yxEjajBLZtrQAAAAAAAAAAAAMAACACP0VUREtLM0tMSVMwVTRGS1QySzFLTk1TV0FNRC4u. The deadline of fact sheet submission is 11:59pm, July 14th (UTC).
Overview
The competition has been launched at CodaLab, please follow the link to participate:
https://codalab.lri.fr/competitions/559
Temporal relational data is very common in industrial machine learning applications, such as online advertising, recommender systems, financial market analysis, medical treatment, fraud detection, etc. With timestamps to indicate the timings of events and multiple related tables to provide different perspectives, such data contains useful information that can be exploited to improve machine learning performance. However, currently, the exploitation of temporal relational data is often carried out by experienced human experts with in-depth domain knowledge in a labor-intensive trial-and-error manner.
In this challenge, participants are invited to develop AutoML solutions tobinary classification problems for temporal relational data. The provided datasets are in the form of multiple related tables, with timestamped instances. Five public datasets (without labels in the testing part) are provided to the participants so that they can develop their AutoML solutions. Afterward, solutions will be evaluated with five unseen datasets without human intervention. The results of these five datasets determine the final ranking.
To participate, please visit ourchallenge platform, and follow theinstructions to learn details about the problem setup, data, submission interface, evaluation, and get started. We also provided to the participants a starting-kit which includes the demo data, a baseline method, and all things needed tosimulate the running environment on their PCs.
This is the first AutoML competition that focuses on temporal relational data and it will pose new challenges to the participants, as listed below:
- How to automatically generate useful temporal information?
- How to efficiently merge the information provided by multiple related tables?
- How to automatically capture meaningful inter-table interactions?
- How to avoid data leak in an automatic manner, when the data is temporal?
Additionally, participants should also consider:
- How to automatically and efficiently select appropriate machine learning model and hyper-parameters?
- How to make the solution more generic, i.e., how to make it applicable for unseen tasks?
- How to keep the computational and memory cost acceptable?
This challenge has been posted on theKDD Cup official website(Automated Machine Learning Competition Track, Auto-ML Track).
Platform
Participants should log in ourplatformto start the challenge. Please follow the instructions in "Learn the Details - Instructions" to get access to the data, learn the data format and submission interface, and download the starting-kit.
Data
This challenge focuses on the problem ofbinary classification for temporal relational datacollected from real-world businesses. According to the temporal nature of most real-world applications, the datasets are chronologically split into training and testing parts. Both the training and testing parts consist of a main table, a set of related tables, and a relation graph:
- Themain tablecontains instances (with labels in the training part), some features, and timestamps. This is the target of the binary classification.
-Related tablescontain valuable auxiliary information about the instances in the main table and can be utilized to improve predictive performance. Entries in the related tables occasionally have timestamps.
- The relations among data in different tables are described by aRelation Graph. It should be noted that any two tables (main or related table) can have a relation, and any pair of tables can have at most one relation. It is guaranteed that the Relation Graphs are the same in training and testing parts.
The following figure illustrates the form of the datasets:
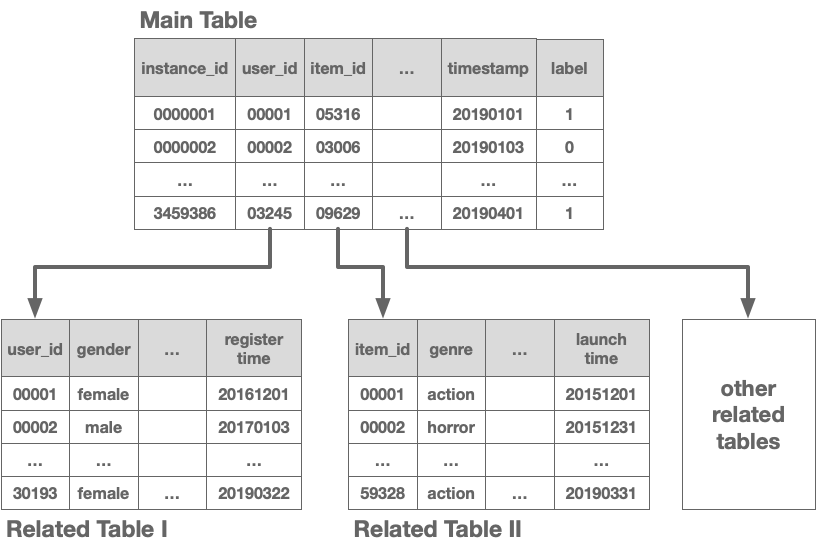
More details about the data can be found on theplatform [Learn the Details - Data].
Rules
Submission & Evaluation
Participantsshould form teams with one or more members.
Teams are required to submit AutoML solutions that automatically build machine learning models by using training main table, related tables and relation graph. Once trained, the models should take the testing main table (labels excluded), related tables, and relation graph as input and predict the testing labels. Solutions will be tested under restricted resources and time that will be the same for every competitor.
A practical AutoML solution should be able to generalize to a wide range of unseen learning tasks. In order to enable the participants to develop and evaluate these solutions, we prepared a total of 10 temporal relational datasets for the competition, five out of which are termed as ‘public datasets’ and the others ‘private datasets’. The challenge comprises three phases:
-Feedback Phase: In this phase, the participants are provided with the training data of five public datasets to develop their AutoML solutions. The code will be uploaded to the platform and participants will receive immediate feedback on the performance of their method in a holdout set. The maximum submission number every day is restricted. Participants can download the labeled training data and the unlabeled testing sets of five public datasets so they can prepare their code submissions at home. The LAST code submission of each team in this phase will be forwarded to the next phase for final testing.
-Check Phase: In this phase participants will be able to check whether their submissions (migrated from the feedback phase) can be successfully evaluated with the five private datasets. Participants will get informed if their submission failed on any of the five private datasets due to time or memory exceeding. Each team has only one chance to correct its submissions. No testing performance will be revealed.
-AutoML Phase: This is the blind test phase with no submission. In this phase, solutions will be tested with their performances on private datasets. Participants’ codes will automatically train machine learning models without human intervention. The final score will be evaluated by the result of the blind testing.
The score of the solution on a dataset is calculated as:
score = (auc - auc_base) / (auc_max - auc_base),
whereaucis the resulting AUC of the solution on the dataset,auc_baseis the AUC of the baseline method on the dataset, andauc_maxis the AUC of the best solution on the dataset. In case thatauc_max < auc_base, all submissions will get 0 scores on the dataset. The baseline method can be found in the starting-kit (see the platform website "Get Started" for more details). The scores of the baseline method, submitted by team "chalearn", are also listed on theleaderboard.
Theaverage scoreon all five public/private datasets will be used to score a solution in the Feedback/AutoML Phases.And the Average score on all five private datasets is used as the final score of a team.
Solutions with better interpretability will be given preference in case there is a tie in the final score. The interpretability of the solutions will be judged by a committee of experts (some experts from the organization team, and some invited experts).
Please note that the final score evaluates the LAST code submission, i.e., the last code submission in the Feedback Phase, or the resubmission in the Check Phase if there is one.
The following figure illustrates how submissions work in both Feedback and AutoML Phases:
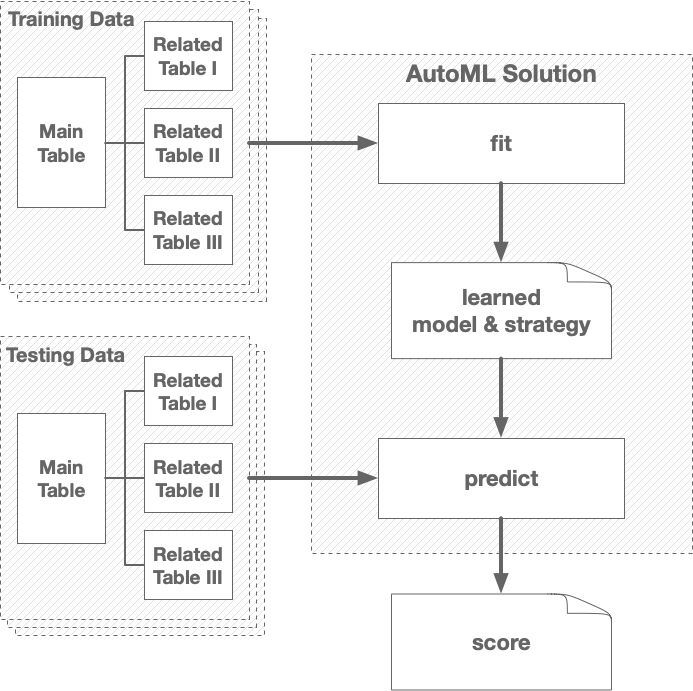
Computational and memory resources are limited in all three phases to ensure that solutions are adequately efficient.
More details about submission and evaluation can be found on theplatform [Learn the Details - Submission/Evaluation].
Terms & Conditions
Please find the terms and conditions on theplatform website [Learn the Details - Terms and Conditions].
Prizes
1st Place: $15,000
2nd Place: $10,000
3rd Place: $5,000
4th - 10th Places: $500 each
Timeline (UTC Time)
- Apr 1st, 2019: Beginning of the competition, the release of public datasets. Participants can start submitting codes and obtaining immediate feedback in the leaderboard.
-
June 26th, 2019, 11:59 p.m. UTC: End of the Feedback Phase; Beginning of the Check Phase; Codes from Feedback phase is migrated automatically to Check Phase.
-
July 4th, 2019, 08:00 a.m. UTC: Notification of check results.
-
July 13th, 2019, 11:59 p.m. UTC: End of the Check Phase; Deadline of code resubmission; Beginning of the AutoML Phase; Organizers start code verification.
-
July 14th, 2019, 11:59 p.m. UTC: Deadline for submitting the fact sheets.
-
July 15th, 2019, 11:59 p.m. UTC: End of the AutoML Phase; Beginning of the post-competition process.
-
July 20th, 2019: Announcement of the KDD Cup Winner.
-
Aug 4th, 2019: Beginning of KDD 2019.
About
Pleasecontact the organizersif you have any problem concerning this challenge.
Sponsors




Advisors
- Isabelle Guyon, Universt ́e Paris-Saclay, France, ChaLearn, USA, (Advisor, Platform Administrator)guyon@chalearn.org
- Qiang Yang, Hong Kong University of Science and Technology, Hong Kong, China, (Advisor, Sponsor)qyang@cse.ust.hk
Committee
- Wei-Wei Tu, 4Pardigm Inc., China, (Coordinator, Platform Administrator, Data Provider, Baseline Provider, Sponsor)tuweiwei@4paradigm.com
- Hugo Jair Escalante, NAOE, Mexico, ChaLearn, USA, (Advisor, Platform Administrator)hugo.jair@gmail.com
- Sergio Escalera, University of Barcelona, Spain, (Advisor)sergio@maia.ub.es
-Evelyne Viegas, Microsoft Research, (Sponsor),evelynev@microsoft.com
- Mengshuo Wang, 4Paradigm Inc., China, (Web Administrator)wangmengshuo@4paradigm.com
- Xiawei Guo, 4Paradigm Inc., China, (Platform Administrator)guoxiawei@4paradigm.com
- Ling Yue,4Paradigm Inc., China, (Platform Administrator)yueling@4paradigm.com
-Jian Liu, 4Paradigm Inc., China, (Operations)liujian@4paradigm.com
- Hai Wang, 4Paradigm Inc., China, (Data Provider)wanghai@4paradigm.com
- Wenhao Li, 4Paradigm Inc., China, (Baseline Provider)liwenhao@4paradigm.com
- Yuanfei Luo, 4Paradigm Inc., China, (Data Provider, Baseline Provider)luoyuanfei@4paradigm.com
- Jingsong Wang, 4Paradigm Inc., China, (Logo Designer)wangjingsong@4paradigm.com
- Runxing Zhong, 4Paradigm Inc., China, (Baseline Provider)zhongrunxing@4paradigm.com
- Yadong Zhao, 4Paradigm Inc., China, (Operations, Web Administrator)zhaoyadong@4paradigm.com
- Feng Bin,4Paradigm Inc., China, (Platform Developer)binfeng@4paradigm.com
- Xiaojie Yu,4Paradigm Inc., China, (Platform Developer)yuxiaojie@4paradigm.com
- Yuanmeng Huang, 4Paradigm Inc., China, (Web Administrator)huangyuanmeng@4paradigm.com
- Shiwei Hu,4Paradigm Inc., China, (Sponsor)hushiwei@4paradigm.com
- Yuqiang Chen, 4Paradigm Inc., China, (Sponsor)chenyuqiang@4paradigm.com
- Wenyuan Dai, 4Paradigm Inc., China, (Sponsor)daiwenyuan@4paradigm.com
Organization Institutes
AboutAutoML
Previous AutoML Challenges:
AutoML workshops can be foundhere.
Microsoft research blog post on AutoML Challenge can be foundhere.
KDD Nuggets post on AutoML Challenge can be foundhere.
I. Guyon et al.A Brief Review of the ChaLearn AutoML Challenge: Any-time Any-dataset Learning Without Human Intervention. ICML W 2016.link
I. Guyon et al.Design of the 2015 ChaLearn AutoML challenge. IJCNN 2015.link
Springer Series on Challenges in Machine Learning.link
Q. Yao et al.Taking Human out of Learning Applications: A Survey on Automated Machine Learning. (a comprehensive survey on AutoML).link
About 4Paradigm Inc.
Founded in early 2015,4Paradigmis one of the world’s leading AI technology and service providers for industrial applications. 4Paradigm’s flagship product – the AI Prophet – is an AI development platform that enables enterprises to effortlessly build their own AI applications, and thereby significantly increase their operation’s efficiency. Using the AI Prophet, a company can develop a data-driven “AI Core System”, which could be largely regarded as a second core system next to the traditional transaction-oriented Core Banking System (IBM Mainframe) often found in banks. Beyond this, 4Paradigm has also successfully developed more than 100 AI solutions for use in various settings such as finance, telecommunication and internet applications. These solutions include, but are not limited to, smart pricing, real-time anti-fraud systems, precision marketing, personalized recommendation and more. And while it is clear that 4Paradigm can completely set up a new paradigm that an organization uses its data, its scope of services does not stop there. 4Paradigm uses state-of-the-art machine learning technologies and practical experiences to bring together a team of experts ranging from scientists to architects. This team has successfully built China’s largest machine learning system and the world’s first commercial deep learning system. However, 4Paradigm’s success does not stop there. With its core team pioneering the research of “Transfer Learning,” 4Paradigm takes the lead in this area, and as a result, has drawn great attention of worldwide tech giants.
About ChaLearn
ChaLearnis a non-profit organization with vast experience in the organization of academic challenges. ChaLearn is interested in all aspects of challenge organization, including data gathering procedures, evaluation protocols, novel challenge scenarios (e.g., competitions), training for challenge organizers, challenge analytics, resultdissemination and, ultimately, advancing the state-of-the-art through challenges.
About KDD 2019 Conference
The annual KDD conference is the premier interdisciplinary conference bringing together researchers and practitioners from data science, data mining, knowledge discovery, large-scale data analytics, and big data.
KDD 2019Conference:
- August 4 - 8, 2019
- Anchorage, Alaska USA
- Dena’ina Convention Center and William Egan Convention Center
About Other 2019 KDD Cup Competitions
KDD Cupis the annual Data Mining and Knowledge Discovery competition organized by ACM Special Interest Group on Knowledge Discovery and Data Mining, the leading professional organization of data miners. SIGKDD-2019 will take place in Anchorage, Alaska, US from August 4 - 8, 2019. The KDD Cup competition is anticipated to last for 2-4 months, and the winners will be notified by mid-July 2019. The winners will be honored at the KDD conference opening ceremony and will present their solutions at the KDD Cup workshop during the conference.
InKDD Cup 2019, there are three competition tracks:
-Automated Machine Learning Competition Track (Auto-ML Track)(This competition)
-Regular Machine Learning Competition Track (Regular ML Track)
-“Research for Humanity” Reinforcement Learning Competition Track (Humanity RL Track)
AboutKDD Cup Chairs
- Taposh Dutta-Roy(KAISER PERMANENTE)
- Wenjun Zhou(UNIVERSITY OF TENNESSEE KNOXVILLE)
- Iryna Skrypnyk(PFIZER)

