Rank List
The top-3 teams of the competition (and the github URL to their solutions) are:
| Rank | Team Name | github URL |
| 1 | DeepBlueAI | https://github.com/DeepBlueAI/AutoNLP |
| 2 | upwind_flys | https://github.com/upwindflys/AutoNlp |
| 3 | txta | https://github.com/qingbonlp/AutoNLP |
Overview
World Artificial Intelligence Conference (WAIC) 2019 will be held in Shanghai from August 29th to 31st with the theme of "Intelligent Connectivity Infinite Possibilities". AutoNLP is one of the competitions in the Hackathon of WAIC 2019 provided by 4Paradigm, ChaLearn, and Google.The competition has been launched at CodaLab, please follow the link to participate:
https://autodl.lri.fr/competitions/35Text categorization (also known as text classification, or topic spotting) is the task of assigning predefined categories to free-text documents and has important applications in the real world. However, currently, the exploitation of text categorization is often carried out by experienced human experts with in-depth domain knowledge in a labor-intensive trial-and-error manner.
In this challenge, participants are invited to develop AutoNLP solutions tomulti-class text categorization problems. The provided datasets are in the form of text. Five practice datasets, which can be downloaded by the participants, are provided to the participants so that they can develop their AutoNLP solutions offline. Besides that, another five validation datasets are also provided to participants to evaluate the public leaderboard scores of their AutoNLP solutions. Afterward, thetop 10 teams in the public leaderboard that follow the rules of the competitionwill be invited to on-site rounds for the On-site Phase of the competition, and the detailed rules for the On-site Phase will be announced before the on-site rounds. These 10 teams' solutions will be evaluated with five unseen test datasets without human intervention. The results of these five datasets determine the final ranking.Note that participants outside the Chinese Mainland are allowed to participate in the on-site phase remotely.
To participate, please visit ourchallenge platform, and follow theinstructions to learn details about the problem setup, data, submission interface, evaluation, and get started. We also provided the participants with a starting-kit which includes the demo data, a baseline method, and all things needed tosimulate the running environment on their PCs.
This is the first AutoNLP competition that focuses on text categorization and it will pose new challenges to the participants, as listed below:
- How to automatically preprocess the text data for different languages?
- How to automatically handle both long text and short text?
- How to automatically extract useful features from the text data?
- How to automatically design effective neural network structures?
- How to build and automatically select effective pre-trained models?
Additionally, participants should also consider:
- How to automatically and efficiently select appropriate machine learning model and hyper-parameters?
- How to make the solution more generic, i.e., how to make it applicable for unseen tasks?
- How to keep the computational and memory cost acceptable?
Platform
Participants should log in ourplatformto start the challenge. Please follow the instructions inplatform [Get Started]to get access to the data, learn the data format and submission interface, and download the starting-kit.
Dataset
This challenge focuses on the problem ofmulti-class text categorizationcollected from real-world businesses. The datasets consist of content file, label file and meta file, where content file and label file are split into train parts and test parts:
-Content file ({train, test}.data)contains the content of the instances. Each row in the content file represents the content of an instance.
-Label file ({train, dataset_name}.solution)consists of the labels of the instances in one-hot format. Note that each of its lines corresponds to the corresponding line number in the content file.
-Meta file (meta.json)is a json file consisted of the meta information about the dataset, including language, train instance number, test instance number, category number.
The following figure illustrates the form of the datasets:
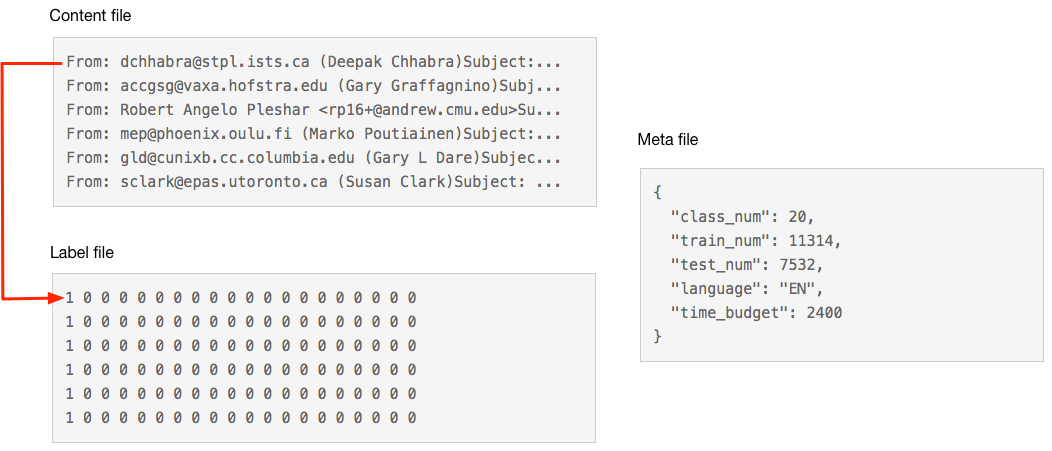
We thanks Tsinghua University and Fudan University for providing two practice datasets.
More details about the data can be found on theplatform [Learn the Details - Dataset].
Rules
Submission & Evaluation
Participantsshould form teams with one or more members.
Teams are required to submit AutoNLP solutions that automatically build machine learning models by using training data. Once trained, the models should take the testing data as input and predict the testing labels. Solutions will be tested under restricted resources and time that will be the same for every competitor.
A practical AutoNLP solution should be able to generalize to a wide range of unseen learning tasks. In order to enable the participants to develop and evaluate these solutions, we prepared a total of 15 text categorization datasets for the competition, five out of which are termed as ‘practice datasets’, five out of which are termed as ‘validation datasets’ and the others ‘test datasets’. The challenge comprises two phases:
-On-line Phase: In this phase, the participants are provided with five practice datasets which can be downloaded, so that they can develop their AutoNLP solutions offline. Then, the code will be uploaded to the platform and participants will receive immediate feedback on the performance of their method at another five validation datasets. The maximum submission number every day is restricted. Thetop 10 teams in the public leaderboard that follow the rules of the competitionwill be invited to on-site rounds for the On-site phase of the competition, and the ranking in the public leaderboard is determined by the LAST code submissions of the participants.
-On-site Phase: This is the blind test phase with no submission. In this phase, solutions will be tested with their performances on five test datasets. Participants’ codes will automatically train machine learning models without human intervention. The final score will be evaluated by the result of the blind testing. The detailed rules for the On-site Phase will be announced before the on-site rounds, andparticipants outside the Chinese Mainland are allowed to participate in the On-site Phase remotely.
The score of the solution on a dataset is calculated asthe Area under Learning Curve (ALC). To better describe this metric, we first explain the evaluation protocol in both On-line and On-site Phases. Here is some pseudo-code of the evaluation protocol:
# For each dataset, our evaluation program calls the model constructor:
# The total time of import Model and initialization of Model should not exceed 20 minutes
from model import Model
M =Model(metadata=dataset_metadata)
remaining_time budget = overall_time_budget
start_time = time()
# Ingestion program calls multiple times train and test:
repeat until M.done_training or remaining_time_budget < 0
{
# Only the runtime of the train and test function will be counted into the time budget
start_time = time.time() M.train(training_data, remaining_time_budget)
remaining_time_budget -= time.time() - start_time
start_time = time.time()
results = M.test(test_data, remaining_time_budget)
remaining_time_budget -= time.time() - start_time
# Results made available to scoring program (run in separate container)
save(results)
} Firstly, a model is initialized with the meta data; then the execution process enters a cyclic process, where'train'and'test'will be repeatedly invoked until'done_training'is set to True or the time budget is exhausted. Meanwhile, a record about the prediction of the test data will be generated when'test'is invoked at each cyclic step.Note that, the model will be initialized only one time during the submission process, so the participants can control the model behavior by its member variables.
The participants can train in batches of pre-defined duration to incrementally improve their performance until the time limit is attained. In this way, we can plot learning curves: "performance" as a function of time. Each time the "train" method terminates, the "test" method is called and the results are saved, so the scoring program can use them, together with their timestamp.
For multi-class problems, each class is considered a separate binary classification problem, and we compute the normalized AUC (or Gini coefficient)
2 * AUC - 1
as the score for each prediction, here AUC is the average of the usualarea under ROC curve(ROC AUC) of all the classes in the dataset.
For each dataset, we compute theArea under Learning Curve (ALC). The learning curve is drawn as follows:
- at each timestamp t, we compute s(t), the normalized AUC (see above) of themost recentprediction. In this way, s(t) is astep functionw.r.t time t;
-
in order to normalize time to the [0, 1] interval, we perform a time transformation by
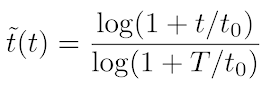
where T is the time budget (of default value 2400 seconds = 40 minutes) and t0 is a reference time amount (of default value 60 seconds). -
then compute the area under learning curve using the formula
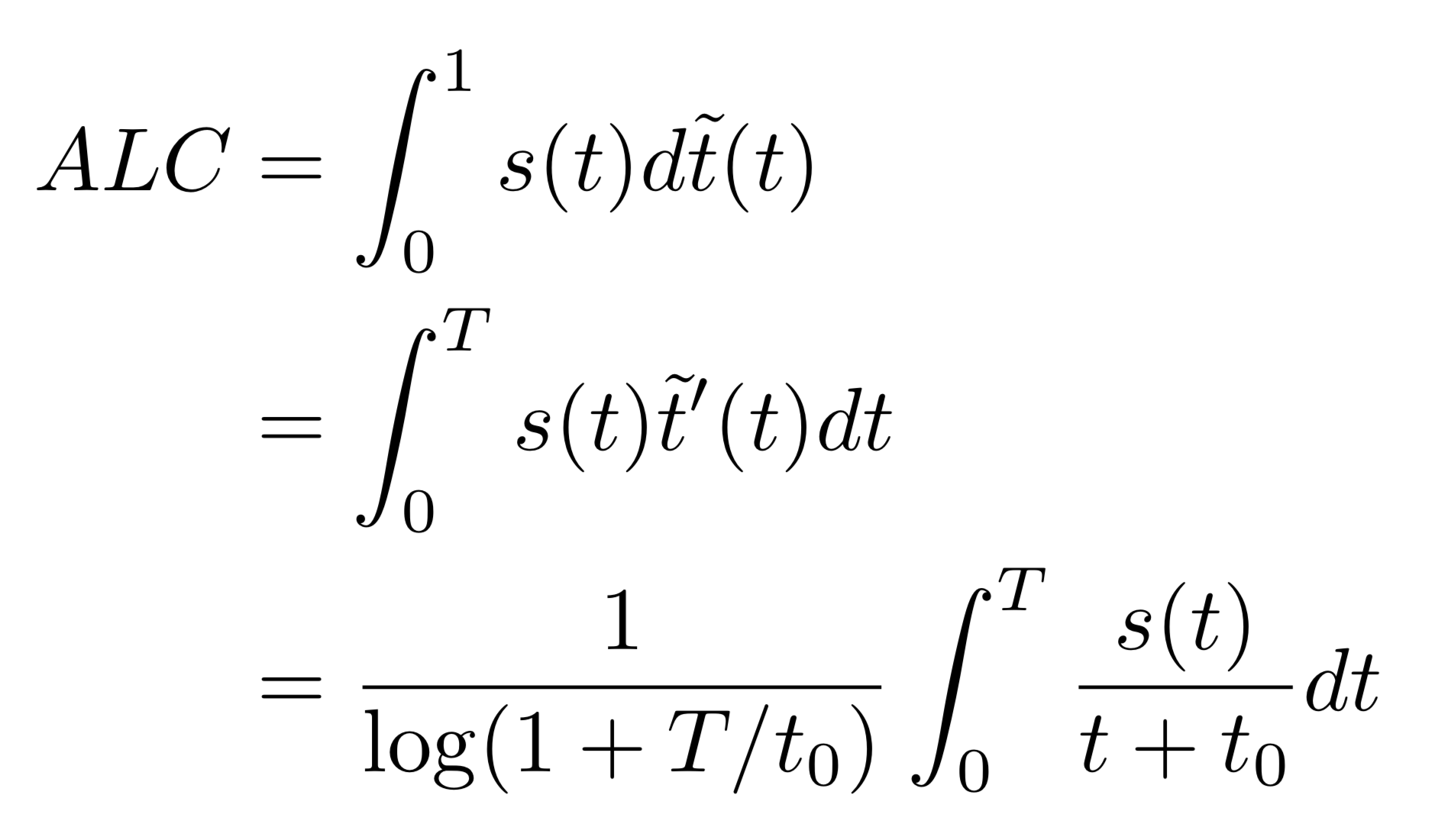
we see that s(t) is weighted by 1/(t + t0)), giving a stronger importance to predictions made at the beginning of the learning curve.
After we compute the ALC for all 5 datasets, theoverall rankingis used as the final score for evaluation and will be used in the leaderboard. It is computed by averaging the ranks (among all participants) of ALC obtained on the 5 datasets.
Examples of learning curves:
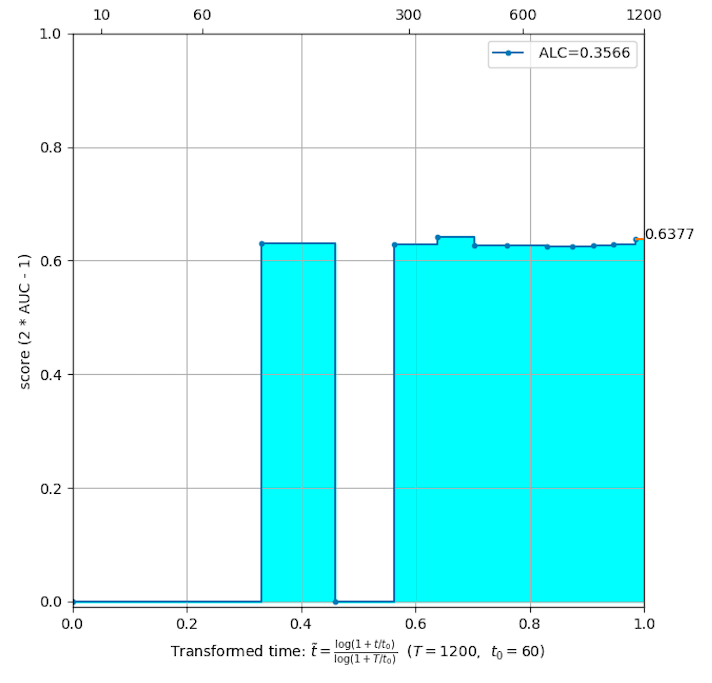
Computational and memory resources are limited in all two phases to ensure that solutions are adequately efficient.
More details about submission and evaluation can be found on theplatform [Get Started - Evaluation].
Terms & Conditions
Please find the challenge rules on theplatform website [Get Started - Challenge Rules].
Prizes
- 1st Place: $4,500
- 2ndPlace: $2,250
- 3rdPlace: $750
Timeline
UTC+8 Time (Beijing Time)
-
Aug 2rd, 2019, 11:59 a.m.: Beginning of the competition, the release of practice datasets. Participants can start submitting codes and obtaining immediate feedback in the leaderboard.
-
Aug 21th, 2019, 23:59 p.m.: End of the On-line Phase
-
Aug 22th, 2019, 11:59 a.m.: Announcement of the top 10 teams in the public leaderboard that follow the rules of the competition.
-
Aug 29th, 2019, 8:59 a.m.: Beginning of the On-site Phase.
-
Aug 31th, 2019: Defense & Announcement of the final winners.
UTC Time
-
Aug 3rd, 2019, 3:59 a.m.: Beginning of the competition, the release of practice datasets. Participants can start submitting codes and obtaining immediate feedback in the leaderboard.
-
Aug 21th, 2019, 15:59 p.m.: End of the On-line Phase
-
Aug 22th, 2019, 3:59 a.m.: Announcement of the top 10 teams on the public leaderboard that follow the rules of the competition.
-
Aug 29th, 2019, 00:59 a.m.: Beginning of the On-site Phase.
-
Aug 31th, 2019: Defense & Announcement of the final winners.
About
Pleasecontact the organizersif you have any problem concerning this challenge.
Sponsors



Advisors
- Isabelle Guyon, Universt ́e Paris-Saclay, France, ChaLearn, USA, (Advisor, Platform Administrator)guyon@chalearn.org
- Qiang Yang, Hong Kong University of Science and Technology, Hong Kong, China, (Advisor, Sponsor)qyang@cse.ust.hk
- Sinno Jialin Pan, Nanyang Technological University, Singapore, (Advisor, Sponsor)sinnopan@ntu.edu.sg
- Wei-Wei Tu, 4Pardigm Inc., China, (Coordinator, Platform Administrator, Data Provider, Baseline Provider, Sponsor)tuweiwei@4paradigm.com
Committee
- Yuanfei Luo, 4Paradigm Inc., China, (Data Provider, Baseline Provider)luoyuanfei@4paradigm.com
- Hugo Jair Escalante, NAOE, Mexico, ChaLearn, USA, (Advisor, Platform Administrator)hugo.jair@gmail.com
- Sergio Escalera, University of Barcelona, Spain, (Advisor)sergio@maia.ub.es
- Evelyne Viegas, Microsoft Research, (Sponsor)evelynev@microsoft.com
- Wenhao Li, 4Paradigm Inc., China, (Baseline Provider)liwenhao@4paradigm.com
- Hao Zhou, 4Paradigm Inc., China, (Web Administrator)zhouhao@4paradigm.com
- Hai Wang, 4Paradigm Inc., China, (Data Provider)wanghai@4paradigm.com
- Xiawei Guo, 4Paradigm Inc., China, (Platform Administrator)guoxiawei@4paradigm.com
- Ling Yue,4Paradigm Inc., China, (Platform Administrator)yueling@4paradigm.com
-Jian Liu, 4Paradigm Inc., China, (Operations)liujian@4paradigm.com
- Chutong Li, 4Paradigm Inc., China, (Baseline Provider)lichutong@4paradigm.com
- Zhengying Liu, U. Paris-Saclay; UPSud, France, (Platform Provider)zhengying.liu@inria.fr
- Zhen Xu, Ecole Polytechnique and U. Paris-Saclay; INRIA, France, (Platform Provider)zhen.xu@polytechnique.edu
- Yuqiang Chen, 4Paradigm Inc., China, (Sponsor)chenyuqiang@4paradigm.com
- Wenyuan Dai, 4Paradigm Inc., China, (Sponsor)daiwenyuan@4paradigm.com
Organization Institutes
AboutAutoML
Previous AutoML Challenges:
About 4Paradigm Inc.
Founded in early 2015,4Paradigmis one of the world’s leading AI technology and service providers for industrial applications. 4Paradigm’s flagship product – the AI Prophet – is an AI development platform that enables enterprises to effortlessly build their own AI applications, and thereby significantly increase their operation’s efficiency. Using the AI Prophet, a company can develop a data-driven “AI Core System”, which could be largely regarded as a second core system next to the traditional transaction-oriented Core Banking System (IBM Mainframe) often found in banks. Beyond this, 4Paradigm has also successfully developed more than 100 AI solutions for use in various settings such as finance, telecommunication and internet applications. These solutions include, but are not limited to, smart pricing, real-time anti-fraud systems, precision marketing, personalized recommendation and more. And while it is clear that 4Paradigm can completely set up a new paradigm that an organization uses its data, its scope of services does not stop there. 4Paradigm uses state-of-the-art machine learning technologies and practical experiences to bring together a team of experts ranging from scientists to architects. This team has successfully built China’s largest machine learning system and the world’s first commercial deep learning system. However, 4Paradigm’s success does not stop there. With its core team pioneering the research of “Transfer Learning,” 4Paradigm takes the lead in this area, and as a result, has drawn great attention of worldwide tech giants.
About ChaLearn
ChaLearnis a non-profit organization with vast experience in the organization of academic challenges. ChaLearn is interested in all aspects of challenge organization, including data gathering procedures, evaluation protocols, novel challenge scenarios (e.g., competitions), training for challenge organizers, challenge analytics, resultdissemination and, ultimately, advancing the state-of-the-art through challenges.

